01-1. Java와 객체 지향 프로그래밍의 이해
객체 지향의 5가지 설계 원칙 [ SOLID ]
SOLID 원칙은 시간이 지나도 유지보수와 확장이 쉬운 소프트웨어를 만들기 위해 사용된다.
다음과 같은 원칙으로 구성되며, 객체 지향의 5가지 설계 원칙으로 불리기도 한다.
Single Responsibility Principle(SRP), 단일 책임 원칙
Open-Closed Principle(OCP), 개방-폐쇄 원칙
Liskov Substitution Principle(LSP), 리스코프 치환 원칙
Interface Segregation Principle(ISP), 인터페이스 분리 원칙
Dependency Inversion Principle(DIP), 의존관계 역전 원칙
단일 책임 원칙
클래스는 하나의 책임만 가진다.
이때 책임이란 뭘까?
'변경하려는 이유'를 책임으로 정의한다.
어떤 클래스나 모듈은 변경하려는 단 하나의 이유만을 가져야 한다는 뜻이다.
좀 더 쉽게 접근하려면, 책임=기능이라고 생각해 보자.
한 객체에 기능이 많아질수록 클래스 내부에서 서로 다른 역할을 수행하는 코드끼리 강하게 결합될 가능성이 높아진다.
한 기능에 대한 변경사항이 발생하면, 이 기능을 사용하는 다른 기능들에 영향을 주게 될 가능성이 높아지는 것이다.
따라서 변경사항이 발생했을 때 그 변경에 영향을 받는 기능만 모아둔 클래스만 수정하면 되도록,
클래스가 변경되는 이유가 한 가지여야 한다는 것이 단일 책임 원칙의 핵심이다.
여러 책임을 가지고 있으면 클래스가 변경되는 이유도 여러 가지가 되기 때문이다.
코드의 유지보수성을 높이기 위해서는 한 클래스에 한 책임만 가지도록 하자!
개방-폐쇄 원칙
확장에는 열려있어야 하고, 변경에는 닫혀있어야 한다.
즉, 기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 설계되어야 한다는 의미이다.
이는 평소 우리가 사용하던 '추상화'와 '다형성'을 통해 구현할 수 있다.
자주 사용하는 코드를 추상화함으로써 기존 코드를 수정하지 않고 상속 등을 통해 기능을 유연하게 확장하는 것이다.
리스코프 치환 원칙
하위 타입 객체는 상위 타입 객체에서 가능한 행위를 수행할 수 있어야 함
자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행이 보장되어야 한다는 의미이다.
즉, 상위 타입의 객체(부모 클래스)를 하위 타입의 객체(자식 클래스)로 치환해도 코드가 원래 의도대로 작동해야 한다는 의미이다.
이는 우리가 사용하는 '다형성'의 원리를 나타낸 원칙이라고 볼 수 있다.
인터페이스 분리 원칙
클라이언트는 자신이 사용하는 메서드에만 의존해야 함
범용적인 인터페이스보다는 사용자가 실제로 사용하는 인터페이스를 만들어야 한다는 의미이다.
인터페이스를 상속받은 클래스가 자신이 사용하지 않는 부분을 억지로 구현해야 하지 않도록 인터페이스를 잘게 분리함으로써 클라이언트의 목적과 용도에 적합한 인터페이스만 제공하는 것이다.

의존관계 역전 원칙
의존 관계를 맺을 때, 변하기 쉬운 것(구체적인 것) 보다는 변하기 어려운 것(추상적인 것)에 의존해야 함
객체에서 어떤 클래스를 참조해서 사용해야 한다면, 클래스가 아니라 그 상위 요소(추상 클래스/인터페이스)를 참조하라는 의미이다.
하위 모듈에 변화가 있을 때마다 상위 모듈의 코드를 자주 수정하지 않도록, 구체화된 클래스에 의존하기보다는 추상 클래스나 인터페이스에 의존하라는 것이다.
즉 '추상화'를 이용하라는 뜻으로, 앞서 설명한 개방-폐쇄 원칙과 밀접한 관계를 가진다.
정리하자면?
단일 책임 원칙과 인터페이스 분리 원칙은 변경에 대한 연쇄 작용으로부터 자유로울 수 있도록 하여 객체가 크고 복잡해지는 것을 막아주며, 리스코프 치환 원칙과 의존관계 역전 원칙은 자주 변화되는 부분을 추상화(DIP)하고 다형성을 이용(LSP)하여 용이한 확장을 도움으로써 개방-폐쇄 원칙(기존 코드 변화 X, 기능 확장 O)을 지킬 수 있도록 한다.
클래스와 인스턴스
[ 클래스와 인스턴스 ]
클래스 : 하나의 역할을 위임받고, 해당 역할을 수행하는데 필요한 속성(멤버 변수, field)과 행위(멤버 함수, method)를 정의한 것
클래스는 객체 모양을 선언한 틀이라고 볼 수 있으며, 클래스를 통해 캡슐화가 실현된다.
// Animal 클래스 정의
public class Animal {
private String name;
private int age;
public void eat() {
System.out.println("동물이 음식을 먹습니다.");
}
public void speak() {
System.out.println("동물이 소리를 냅니다.");
}
public void love() {
System.out.println("동물이 사랑을 합니다.");
}
}
객체 : 클래스의 모양대로 생성된 실체(instance)로, 실제로 메모리를 할당받아 데이터화된 객체
public void main(String[] args) {
Animal animal = new Animal(); // Animal 클래스의 객체
}

[ 자바의 new 연산자 ]
new 연산자는 Heap 메모리 영역에 객체의 공간을 할당한 후, 메모리 주소를 반환하고 해당 클래스의 생성자를 실행시킨다.
new 연산자로 생성된 객체는 같은 값을 가지고 있어도 각각 서로 다른 메모리를 할당받기 때문에 서로 다른 데이터로 분류된다.
- new를 사용한 경우
public class NewTest {
public static void main(String[] args) {
String dogOne = new String("dog");
String dogTwo = new String("dog");
// identityHashCode() -> 메모리 주소를 숫자 값으로 반환해주는 메서드
System.out.println(System.identityHashCode(dogOne)); // 1456208737
System.out.println(System.identityHashCode(dogTwo)); // 288665596
}
}
- new를 사용하지 않은 경우
두 변수의 메모리 주소 값이 동일하게 나온다.
String testOne = "Test";
String testTwo = "Test";
System.out.println(System.identityHashCode(testOne)); //13648335
System.out.println(System.identityHashCode(testTwo)); //13648335
[ 자바의 생성자 ]
자바에서는 클래스를 정의할 때 생성자를 선언하지 않을 경우 자동으로 아무 기능도 하지 않는 기본 생성자가 선언된다.
// 생성자의 구조
public 클래스 명과 동일 (외부에서 필요한 인자) {
실행할 로직
}
// 위에서 정의했던 Animal 클래스의 기본 생성자
public Animal() { }
# 생성자의 특징
- 생성자의 이름은 클래스 이름과 동일해야 한다.
- 생성자는 리턴값이 존재하지 않는다.
- 생성자는 객체가 생성될 때 자동으로 가장 먼저 호출된다.
- 매개변수에 조건에 따라 여러 개의 생성자를 작성할 수 있다.
# 생성자를 사용하는 이유
- 생성자를 사용하지 않은 경우
public class ConvenienceStore {
// 편의점 브랜드
private String brand;
// 편의점 주소
private String address;
// 직원 수
private int staffCount;
// 방문자 수
private int visitorCount;
public void addStaffCount() {
staffCount++;
}
public int getStaffCount() {
return staffCount;
}
public void addVisitorCount() {
visitorCount++;
}
public void initVisitorCount() {
visitorCount = 0;
}
public int getVisitorCount() {
return visitorCount;
}
}
public static void main(String[] args) {
ConvenienceStore firstGS = new ConvenienceStore();
// 인스턴스 하나 생성하는 데 코드가 너무 길다 ...
firstGS.brand = "GS 25";
firstGS.address = "지구 어딘가";
firstGS.staffCount = 8;
firstGS.visitorCount = 1000;
firstGS.addStaffCount();
firstGS.addVisitorCount();
firstGS.printConvenienceStoreInfo();
}
- 생성자를 사용한 경우
public class ConvenienceStore {
// 편의점 브랜드
String brand;
// 편의점 주소
String address;
// 직원 수
int staffCount;
// 방문자 수
int visitorCount;
public ConvenienceStore(String brand, String address, int staffCount, int visitorCount) {
this.brand = brand;
this.address = address;
this.staffCount = staffCount;
this.visitorCount = visitorCount;
}
public void addStaffCount() {
staffCount++;
}
public int getStaffCount() {
return staffCount;
}
public void addVisitorCount() {
visitorCount++;
}
public void initVisitorCount() {
visitorCount = 0;
}
public int getVisitorCount() {
return visitorCount;
}
public void printConvenienceStoreInfo() {
System.out.println("편의점 브랜드: " + brand);
System.out.println("편의점 주소: " + address);
System.out.println("편의점 직원 수: " + staffCount);
System.out.println("편의점 방문자 수: " + visitorCount);
}
}
public static void main(String[] args) {
// 인스턴스 하나 생성할 때 코드가 확 줄었다 굿~
ConvenienceStore firstGS = new ConvenienceStore("GS 25", "지구 어딘가", 8, 0);
firstGS.addStaffCount();
firstGS.addVisitorCount();
firstGS.printConvenienceStoreInfo();
}
[ 리터럴 ]
리터럴은 프로그램에서 직접 표현한 값으로, 데이터 그 자체를 뜻한다.
int a = 1;위 예제를 보면, a는 변수이고 1은 리터럴이다.
1과 같이 변하지 않는 데이터를 리터럴이라고 부르며, 종류로는 논리, 문자, 정수, 실수, 문자열 리터럴이 있다.

# 논리
논리 리터럴에는 두 개의 논리적인 값(true / false)만 있으며, 자바에서는 참과 거짓을 1, 0으로 표현할 수 없다.
# 문자
자바의 모든 문자들은 Unicode를 사용한다. 정수로 변환될 수 있으며, 더하고 빼는 것과 같은 연산이 가능하다.
유니코드나 직접 입력이 불가능한 문자들에 대해서는 역슬래쉬( \ )를 이용하여 표시할 수 있다.

# 정수
가장 일반적으로 사용되는 데이터 자료형이며, 모든 임의의 정수 값은 정수 리터럴이다.
예를 들어 1, 2, 3, 42는 정수 리터널이다. 또한 정수 리터럴로 10진수, 8진수, 16진수, 2진수를 사용할 수도 있다.
15 → 10진수 리터럴, 15를 의미
015 → 0으로 시작하면 8진수 리터럴, 10진수 값으로 13을 의미
0x15 → 0x로 시작하면 16진수 리터럴, 10진수 값으로 21을 의미
0b0101 → 0b로 시작하면 2진수 리터럴, 10진수 값으로 5를 의미
** 모든 정수형 데이터가 기본적으로 int형이기 때문에 long 데이터 자료형에 정확한 long 리터럴을 지정하기 위해서는 숫자 뒤에 알파벳 L을 추가해줘야 한다.
# 실수
실수 리터럴은 소수점 이하(분수)의 값을 가진 10진수 값들이다.
예를 들어 2.0, 3.1415, -0.6667은 모두 실수 리터럴이다.
double형과 float형이 기본형이며, 숫자 뒤에 알파벳 D를 추가할 수도 있다.
# 문자열
문자열 리터럴은 이중 인용 부호(" “)로 지정하여 사용한다.
String str = "안녕하세요~";
[ static vs final vs static final ]
# static
객체 생성 없이 사용할 수 있는 필드와 메서드를 생성하고자 할 때 활용한다.
따라서 static 키워드를 가진 멤버는 값이 클래스의 모든 인스턴스에 대해 동일하다.
클래스의 모든 인스턴스가 액세스 할 수 있는 전역 변수라고 볼 수 있다.
그러나 static 변수는 상수가 아니므로 언제나 변경될 수 있다.
public class Main {
static int testVal = 1; // static 변수
int val = 3; // 인스턴스 변수
public static void testStatic() { //static 메서드
System.out.println("test");
}
public static void main(String[] args) {
// 오류 발생. static 메서드 내부에서는 외부의 "static 멤버에만" 접근이 가능한데
// val은 static 변수가 아니기 때문
System.out.println(val);
// static 변수이므로 접근 가능
System.out.println(testVal);
// static 변수이므로 접근 가능
System.out.println(Test.a);
// static 메서드이므로 접근 가능
Test.print();
// static 메서드이므로 접근 가능
testStatic();
//////////////////////////////////////
// b값 1 출력 (객체 생성 시 생성자 호출의 a++로 인해 a 값은 1)
Test test1 = new Test();
System.out.println(test1.b);
// b값 1 출력 (객체 생성 시 생성자 호출의 a++로 인해 a 값은 2)
Test test2 = new Test();
System.out.println(test2.b);
// 객체 생성 시 생성자 호출의 a++로 인해 a 값은 3, b 값 1 출력
Test test3 = new Test();
System.out.println(test3.a); // 3
System.out.println(test3.b); // 1
}
}
///////////////////////////////////////
class Test {
static int a = 0; // static 변수
int b = 0; // 인스턴스 변수
Test() {
a++;
b++;
}
static void print() { // static 메서드
System.out.println("static 메소드입니다.");
}
}
# final
final 변수는 값이 저장되면 최종적인 값이 되므로, 수정이 불가능하다.
1) 상수 정의, 2) 메서드, 3) 클래스에 사용할 수 있으며,
1) 상수에 언제든 값을 한번 저장하고 바꾸지 않을 때
2) 메서드를 오버라이딩 하지 못하게 할 때
3) 클래스를 상속하지 못하게 할 때
로 구분할 수 있다.
상수 정의 시 final 변수에 값을 저장하는 방법에는 아래와 같은 두 가지가 있다.
public class Shop {
final int closeTime = 21; // 선언과 동시에 초기화
final int openTime; // 선언 후 객체를 생성할 때 생성자를 통해 초기화
public Shop(int openTime) {
this.openTime = openTime;
}
}
모든 가게가 오픈 시간은 자유롭지만 한 번 정한 오픈 시간을 바꿀 수 없고, 21시에는 모두 가게를 닫아야 할 때 위와 같이 final 키워드를 이용하면 오픈 시간은 객체마다 다르게 설정이 가능하지만 닫는 시간은 고정되도록 코딩이 가능하다.
#static final
객체마다 값이 바뀌는 것이 아닌 클래스에 존재하는 상수이므로, 선언과 동시에 초기화를 해 주어야 한다.
상수란 변하지 않는 값을 뜻하는데, 위의 final 예시에서 closeTime은 21로 변하지 않지만 openTime은 객체마다 다를 수 있음을 보였으므로 final 자체만으로는 상수를 의미할 수 없다.
따라서 정리하자면
static = 객체가 아닌 클래스에 존재하는 변수,
final = 수정이 불가능하지만 객체마다 값이 다를 수 있음,
static final = 객체가 아닌 클래스에 존재하는 상수(static의 성질), 수정이 불가능하고 모든 객체에 대해 동일한 값을 가짐(final의 성질)
[ this와 this() ]
간단히 설명하자면 this는 인스턴스 자신을 가리키는 참조 변수이고 this()는 생성자를 의미한다.
아래 예제를 통해 자세히 알아보자.
# this
생성자의 매개변수로 선언된 변수의 이름이 인스턴스 변수와 같을 때, 지역변수와 인스턴스 변수를 구분하기 위해 사용한다.
class Car {
String color; // 인스턴스 변수
String gearType; // 인스턴스 변수
int door; // 인스턴스 변수
Car(String color, String gearType, int door){ // 생성자
this.color = color;
this.gearType = gearType;
this.door = door;
}
}** static 메서드에서는 this를 사용하지 못한다.
# this()
this()는 같은 클래스의 다른 생성자를 호출할 때 사용한다.
아래 코드의 Car() 생성자와 Car(String color) 생성자는 모두 this()를 통해 Car(String color, String gearType, int door) 생성자를 호출하고 있다.
class Car {
String color; // 인스턴스 변수
String gearType;
int door;
Car() {
this("white", "auto", 4); // Car(String color, string gearType, int door)를 호출
}
Car(String color) {
this(color, "auto", 4);
}
Car(String color, String gearType, int door) {
this.color = color;
this.gearType = gearType;
this.door = door;
}
}
추상화
프로그래밍에서의 추상화는 클래스를 정의할 때 불필요한 부분들을 생략하고 객체의 속성 중 중요한 것에만 중점을 두어 개략화 하는 것을 말한다.
즉 클래스들의 중요하고 공통된 성질들을 추출하여 부모(super) 클래스를 선정하는 것, 이벤트 발생의 정확한 절차나 방법을 정의하지 않고 대표할 수 있는 표현으로 대체하는 것이다.
객체 지향 프로그래밍의 추상화는 크게 두 가지로 나뉘는데, 객체의 관련 속성만 표시하는 데이터 추상화와 불필요한 세부 정보는 숨기는 제어 추상화가 있다.
# 데이터 추상화
데이터 추상화란, 대상의 가장 본질적이고 공통적인 부분을 추출하여 간단한 개념으로 일반화하는 과정을 말한다.
예를 들어 삼각형, 사각형, 원이라는 객체가 있을 때, 이 객체들의 공통 특징인 도형으로 묶어 이름을 붙이는 것을 데이터 추상화라고 보면 된다.
이처럼 추상화를 하면 할수록 객체의 디테일함이 사라지고 공통된 특징만 남는다.
# 제어 추상화
제어 추상화란, 어떤 클래스의 메소드를 사용하는 사용자에게 해당 메소드의 작동 방식과 같은 내부 로직을 숨기는 것을 말한다.
우리가 자동차를 운전할 때, 자동차의 시동/정지/가속/브레이크 등의 동작만 인지하고 그 메커니즘 혹은 프로세스가 어떻게 동작하는지 알지 못하는 것이 그 예시이다. 만약 자동차를 운전하는 데 소비자가 모든 프로세스를 알아야 한다면 현재처럼 자동차 시장이 발달할 수 없었을 것이다.
캡슐화
[ 캡슐화 ]
캡슐화 : 클래스의 속성과 행위를 하나의 캡슐로 만들어 외부로부터 데이터를 보호하는 것
# 캡슐화를 사용하는 이유
데이터 보호(Data protection) : 외부로부터 클래스에 정의된 속성과 기능들을 보호
데이터 은닉(Data hiding) : 내부의 동작을 감추고 외부에는 필요한 부분만 노출
자바의 경우 데이터 보호와 은닉은 접근 제어자를 통해 구현할 수 있다.
[ 자바의 패키지 ]
접근 제어자를 배우기에 앞서 먼저 패키지라는 개념에 대해 알아보자.
자바의 패키지는 서로 관련이 있는 자바 파일들을 폴더 개념으로 함께 묶음으로써, 효율적인 파일 관리를 할 수 있게 도와준다.
자바의 패키지는 .(dot)으로 구분된다.
ex) sopt.user.User
[ 자바의 접근제어자 ]
- public
public 접근제어자가 붙은 변수, 메서드는 어떤 클래스에서라도 접근이 가능하다. - protected
protected가 붙은 변수, 메서드는 동일 패키지의 클래스 또는 해당 클래스를 상속받은 다른 패키지의 클래스에서만 접근이 가능하다. - default
접근 제어자를 별도로 설정하지 않는다면 접근 제어자가 없는 변수, 메서드는 default 접근 제어자가 되어 해당 패키지 내에서만 접근이 가능하다. - private
private 이 붙은 변수, 메서드는 해당 클래스에서만 접근이 가능하다.
상속
상속 : 기존에 정의된 클래스를 이어받아 자신만의 속성과 행위를 추가하여 새로운 클래스를 정의하는 것
# 상속을 하는 이유
- 기존에 작성된 클래스를 재활용할 수 있다.
- 부모 클래스를 상속 받은 자식 클래스는 부모 클래스에 정의된 속성과 행위(변수와 메서드)를 다시 선언할 필요가 없다.
- 클래스 간의 계층적 관계를 구성함으로써 다형성의 문법적 토대를 마련한다.
[ 자식 클래스 ]
자식 클래스는 부모 클래스에 존재하는 모든 속성과 행위를 물려 받고, 추가로 본인만의 속성과 행위를 정의한 클래스를 의미한다.
[ Object 클래스 ]
자바에서 Object 클래스는 모든 클래스의 최상위 클래스이다.
따라서 모든 클래스는 Object 클래스의 속성과 행위 즉, 필드와 메서드를 모두 가지고 있다고 말할 수 있다.
또한, 자바의 모든 클래스는 Object 클래스를 상속받기 때문에 상속을 명시하지 않아도 Object 클래스의 모든 필드와 메서드를 사용할 수 있다.
ex) toString(), clone()
[ Super와 Super() ]
# super
super는 자신이 상속받은 부모 클래스에 대한 레퍼런스 변수로, 부모 클래스의 멤버에 접근할 때 사용된다.
super는 주로 객체 안에 있는 부모의 멤버 변수와 자신의 멤버 변수를 구별하기 위해 쓰인다.
class Parent {
int a = 10;
}
class Child extends Parent {
int a = 20;
void display() {
System.out.println(a);
System.out.println(this.a); // 20
System.out.println(super.a); // 10
}
}
public class Inheritance {
public static void main(String[] args) {
Child ch = new Child();
ch.display();
}
}
# super()
super( )는 자식 클래스의 생성자에서 부모 클래스의 생성자를 호출하기 위해서 사용된다.
- super( )는 생성자 코드안에서 사용 될 때, 다른 코드에 앞서 첫줄에 사용되어야 한다.
- 또한, 자식 클래스의 모든 생성자는 부모 클래스의 생성자를 포함하고 있어야 한다. 만약 자식 클래스의 생성자에 부모 클래스의 생성자가 지정되어 있지 않다면 컴파일러가 자동으로 부모 클래스의 기본 생성자를 호출한다. 이때, 부모 클래스에 매개변수가 있는 생성자만 있고, 기본 생성자가 없어 호출할 수 없다면 오류가 발생한다.
class Parent{
int a;
Parent(int n) {
a = n;
}
}
class Child extends Parent() {
int b;
Child() {
// 부모 클래스에 기본 생성자인 Parent()가 존재하지 않으므로 오류 발생
super()
b = 10;
}
}
위 오류를 해결하는 방법에는 두 가지가 있다.
1) 부모 클래스에 기본 생성자 선언
class Parent{
int a;
Parent() { // 기본 생성자 추가
int a = 10;
}
Parent(int n) {
a = n;
}
}
class Child extends Parent() {
int b;
Child() {
super()
b = 10;
}
}
2) 오버로딩 된 생성자의 매개변수에 super()의 인자를 일치시키기
class Parent{
int a;
Parent(int n) { // 오버로딩 된 생성자
a = n;
}
}
class Child extends Parent() {
int b;
Child() {
super(20) // 인자 일치시키기
b = 10;
}
}다형성
[ 다형성 ]
다형성 : 하나의 객체나 메서드가 각각 여러 가지의 다른 형태를 가질 수 있는 것
# 자바에서의 다형성
- 오버라이딩 & 오버로딩
- 객체의 참조 변수 형 변환
- 인터페이스
- 추상 클래스
# 다형성이 필요한 이유
- 유지보수를 용이하게 해 준다.
- 코드의 재사용성이 증가한다.
- 클래스 간의 의존성을 줄일 수 있다.
[ 오버라이딩 ]
오버라이딩 : 부모 클래스의 메서드(동작)을 재정의 하는 것
# 오버라이딩의 특징
- 오버라이드 하려고 하는 메서드가 부모 클래스에 존재해야 한다.
- 메서드의 이름, 파라미터 타입과 개수, 리턴 타입이 같아야 한다.
부모 클래스
public class Animal {
private String species;
private String name;
private int age;
public void speak() {
System.out.println("동물이 소리를 냅니다.");
}
public void drink() {
System.out.println("동물이 물을 마십니다.");
}
}
오버라이딩 구현
public class Dog extends Animal {
private String gender;
public void walk() {
System.out.println("강아지가 산책을 합니다.");
}
@Override
public void speak() {
System.out.println("월월");
}
}@Override annotation을 사용하지 않아도 에러가 발생하지는 않지만, 휴면 이슈를 줄이기 위해 선언하는 것을 추천한다.
[ 오버로딩 ]
오버로딩 : 같은 이름의 메서드에서 매개변수의 유형과 개수를 다르게 하여 다양한 유형의 호출에 응답할 수 있도록 한 것
# 오버로딩의 특징
- 메서드 이름이 동일해야 한다.
- 리턴 타입은 같거나 달라도 된다.
- 파라미터의 개수가 달라야 하고, 만약 같은 경우에는 데이터 타입이 달라야 한다.
public class Calculator {
Character operator;
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
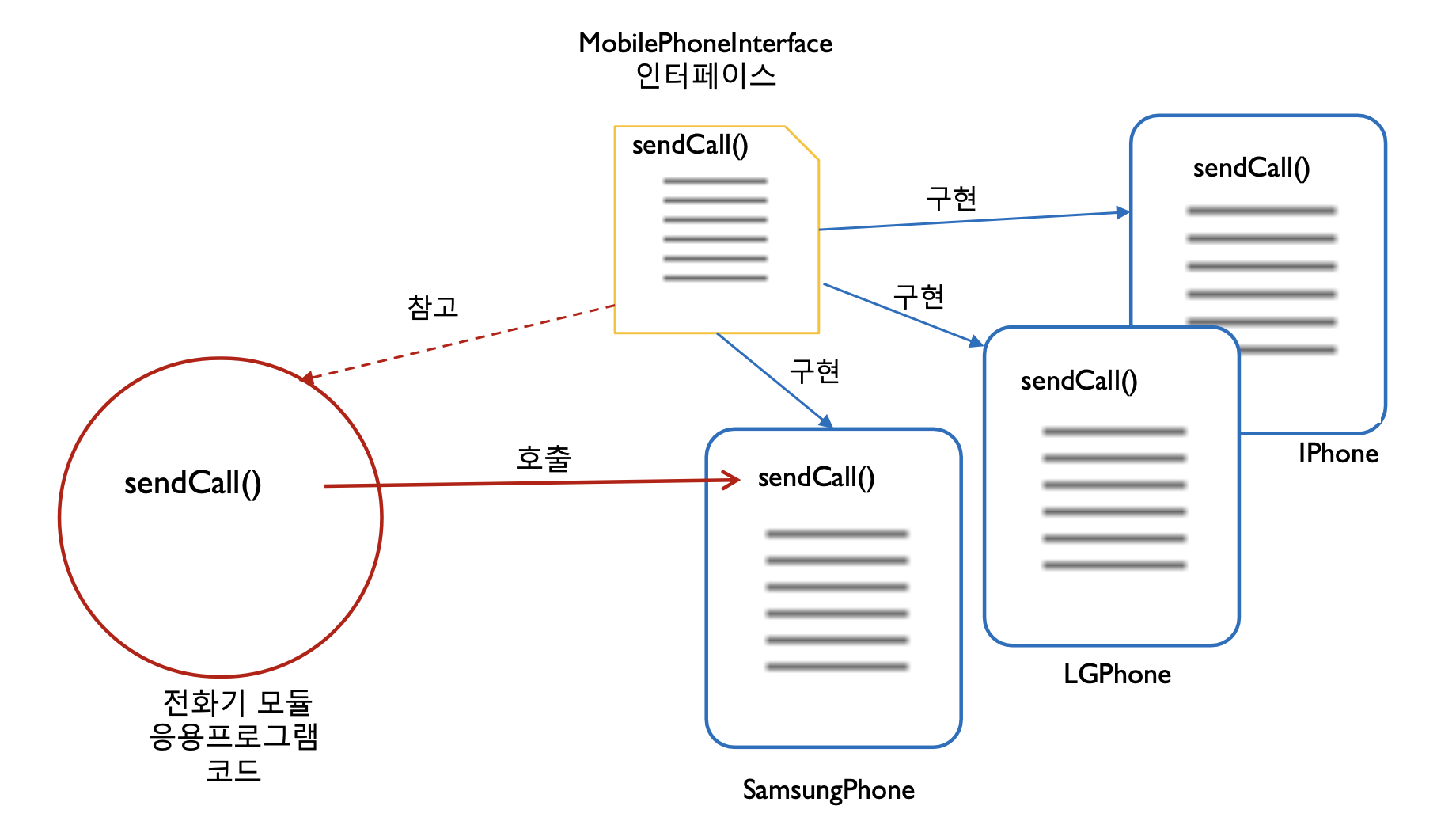
[ 자바 인터페이스 ]
인터페이스 : 다른 클래스를 작성할 때 기본이 되는 틀을 제공하면서, 클래스 간의 중간 매개 역할까지 담당하는 일종의 추상 클래스를 의미한다. 쉽게 설명하자면 객체의 사용 방법에 대한 가이드라인이라고 볼 수 있다. 추상 메서드와 상수로만 이루어져 있으며, 구현된 코드가 없다.
# 인터페이스의 특징
- 다중 상속이 가능하다. (클래스는 다중 상속이 불가능하지만 인터페이스는 가능함)
- 생성자가 존재하지 않는다.
- 인터페이스를 상속 받은 클래스는 부모 인터페이스의 추상 메서드를 모두 오버라이딩 해야 한다.
- 클래스 간의 결합도를 낮출 수 있다.
ex ) public abstract int getAge()와 같은 추상 메서드가 있을 때, 이미 input 값과 output 값이 고정적으로 존재하기 때문에 이 메서드를 사용하는 객체에서 해당 메서드에 미치는 영향은 매우 적다. (확장에 열려있고 변경에는 닫혀 있다)
public interface Car {
public abstract void turnOn();
public abstract void turnOff();
}public class SportsCar implements Car {
@Override
public void turnOn() {
System.out.println("스포츠카 시동 켜기");
}
@Override
public void turnOff() {
System.out.println("스포츠카 시동 끄기");
}
}
인터페이스는 인터페이스를 상속받을 수 있으며, 자식 인터페이스의 네이밍을 강제하여 객체 간의 통일성을 추구할 수 있다.
클래스가 클래스를 상속 받을 때 → extends
클래스가 인터페이스를 상속 받을 때 → implements
인터페이스가 인터페이스를 상속 받을 때 → extends
[ 추상 클래스 & 메서드 ]
abstract 키워드를 통해 추상 클래스와 메서드를 구현하며, 내부의 작동 로직이 없고 틀만 존재한다.
추상 클래스라면 보통 내부에 추상 메서드가 있으니 상속 받는 자식 클래스에서 구현하라는 의미를 내포한다. 따라서 실제 로직은 추상 클래스를 상속 받은 자식 클래스에서 구현하게 된다.
# 추상 클래스의 종류
- 추상 메서드를 하나라도 포함하는 클래스
abstract class Shape { // 추상 클래스 선언
public Shape() { }
public void paint() { draw(); }
abstract public void draw(); // 추상 메소드
}
- 추상 메서드가 하나도 없지만 abstract로 선언된 클래스
abstract class MyComponent { // 추상 클래스 선언
String name;
public void load(String name) {
this.name = name;
}
}
# 추상 클래스의 특징
- 추상 클래스는 객체로 생성이 불가능하다. (new 추상클래스명();가 불가능함)
- 추상 메서드를 가지고 있는 점을 제외하면 일반적인 클래스와 차이점이 없다.
public abstract class Person {
private String gender;
public abstract void walk();
}
class Student extends Person {
@Override
public void walk() {
System.out.println("학교로 걸어갑니다.");
}
}
[ 인터페이스 vs 추상 클래스 ]
인터페이스와 추상 클래스를 학습하다 보면 드는 의문점이 있을 것이다. 둘 다 그냥 추상 메서드를 만들어서 상속 받는 객체들이 그걸 구현하게 하는 것이 아닌가?
하지만 인터페이스와 추상 클래스는 아래와 같이 존재의 목적이 다르다.
- 인터페이스
함수의 틀만 존재하며 해당 함수의 구현을 강제하기 위한 역할 - 추상 클래스
자식 클래스가 부모 클래스를 상속 받아 부모의 속성과 행위를 이용하고 나아가 기능을 확장하는 역할
또한, 자바는 여러 개의 슈퍼 클래스를 두는 다중 상속을 지원하지 않기 때문에 추상 클래스의 다중 상속 또한 불가능하다. 반면 인터페이스의 다중 구현은 허용되는데, 이는 인터페이스가 해당 인터페이스를 구현한 객체들에 대해 동일한 동작을 약속하기 위해 존재하기 때문이다.
즉, 클래스의 다형성을 실현한다는 점에서는 비슷하지만,
추상 클래스는 서브 클래스에서 필요로 하는 대부분의 기능은 구현하여 두고 서브 클래스가 상속 받아 활용할 수 있도록 하되, 서브 클래스에서 구현할 수밖에 없는 기능만을 추상 메서드로 선언하여 서브 클래스에서 구현하도록 하는 목적을 가진다.
인터페이스는 객체의 기능을 모두 공개한 표준화 문서와 같은 것으로, 개발자에게 인터페이스를 상속 받는 클래스의 목적에 따라 인터페이스의 모든 추상 메서드를 만들도록 한다는 점에서 차이가 있다.
[ 자바의 제네릭 ]
자바의 제네릭 : 특정 타입을 사용자의 필요에 의해 지정할 수 있도록 하는 Generic(일반적인) 타입
제네릭으로 지정할 수 있는 타입은 참조 타입(Reference Type)임에 주의하자.
# 제네릭을 사용하는 이유
- 데이터의 타입 검사를 컴파일 단계에서 할 수 있다.
- 클래스 외부에서 타입을 지정하기 때문에 따로 타입을 체크하고 변환해 줄 필요가 없다.
- 비슷한 기능을 지원하는 경우 코드의 재사용성이 높아진다.
제네릭 타입을 선언할 때 <> 내부에 어떤 단어가 들어가도 상관이 없지만, 코드의 가독성과 원활한 협업을 위해서 자바 개발자들은 대부분 아래의 규칙을 사용한다.
<T>: Type
<E>: Element
<K>: Key
<V>: Value
<N>: Number
제네릭 스택
class Stack<E> {
...
void push(E element) { ... }
E pop() { ... }
...
}
특정 타입으로 구체화
// Stack<Integer>로 구체화 한 경우
...
void push(Integer element) { ... }
Integer pop() { ... }
...
// Stack<String>으로 구체화 한 경우
...
void push(String element) { ... }
String pop() { ... }
...
[ 자바의 데이터 타입 ]
자바의 데이터 타입을 크게 두 가지로 나눠보자면, 원시 타입과 참조 타입이 있다.
- 원시 타입
정수, 실수, 문자, 논리 리터럴등의 실제 데이터 값을 저장하는 타입 - 참조 타입
객체(Object)의 주소를 저장하는 타입으로 메모리 번지 값을 통해 객체를 참조하는 타입
참조 타입은 원시 타입을 제외한 타입들을 말하며, 실제 객체는 힙 영역에 저장되고 참조 타입 변수는 스택 영역에 실제 객체들의 주소를 저장하여, 객체를 사용할 때마다 스택 영역에서 참조 변수에 저장된 객체의 주소를 불러와 사용하는 방식이다.
# 정적 메모리 스택 영역(Stack)
- 메소드 내에서 정의하는 기본 자료형에 해당되는 지역 변수의 데이터 값이 저장되는 공간
- 메소드가 호출될때 스택 영역에 스택 프레임 생성, 스택 프레임에 메소드를 호출한다.
- 메소드가 호출 될 때 메모리에 할당되고 종료되면 메모리에서 사라진다.
- Stack은 후입선출(Last-In-First-Out)의 특성을 가지며, 스코프(Scope)의 범위를 벗어나면 스택 메모리에서 사라진다.
# 동적 메모리 힙 영역(Heap)
- 참조형 데이터 타입을 갖는 객체, 배열 등이 저장되는 공간
- 단, Heap 영역에 있는 오브젝트들을 가리키는 레퍼런스 변수는 stack에 적재된다.
- Heap 영역은 Stack 영역과 다르게 보관되는 메모리가 호출이 끝나더라도 삭제되지 않고 유지되다가 참조하는 변수가 없으면 자바의 가비지 컬렉터가 제거한다.
- Stack은 스레드 갯수마다 각각 생성되지만, Heap은 몇 개의 스레드가 존재하든 상관없이 단 하나의 heap 영역만 존재한다.
